
This page lists recent projects the Data Science team have been involved in, and how we use these to benefit the larger chemistry community.
The categories of projects are:
- Natural Language Processing - those projects where we extract meaning from literature
- Machine Learning from Chemical Data - those projects where we extract and apply patterns found in chemistry
- Behavioural Mining - projects were we model and explore how chemists use chemical data
- Business Analytics - projects where we apply machine learning and statistical inference to develop KPIs, forecasting models and sales leads
Natural Language Processing
Extracting Chemical Names
Chemical names come in a number of flavours, and are complex to extract from written text. Members of the team have previously helped to develop OSCAR and at the RSC we have evolved this work further by using deep learning. Specifically we looked into using bi-direction LSTM networks to learn how to identify chemical names from patents and our corpus.
We found that using an ensemble method (combining using word/token based and character encodings) gave the consistently best results
This method was developed as part of the BioCreative V CEMP competition which is a global scientific natural language processing competition. Details about this work can be found in our Biocreative paper. Our entry was ranked third place, although the difference in the first three places was judged insignificant. The chemlistem code produced is open source and available on bitbbucket.

Finding molecular interactions
We wish to be able to extract chemical meaning from literature. While the first step is extracting the chemical names reliably (See above), the next step is using this information to establish how molecules interact. The interactions depend upon the types of molecule, and we recently have looked at the interactions between small molecules and proteins/biologics.
For those that are interested a paper will shortly be available. In brief we have found that we can improve the models considerably by using transfer learning and custom word embeddings. The custom embeddings use our internal corpus to identify the best word associations, and we train on other corpuses (e.g. PubMed) to allow transfer of knowledge.
We used this know-how in the Text mining chemical-protein interactions task of the Biocreative VI NLP competition, where our entry came in second place.

Extracting meaning from literature
In order to make our authors’ articles more discoverable, and to enhance our database offering, we use a variety of tools to extract meaning from literature, for example:
- automatically identifying categories for papers (and then assigning those categories to new papers)
- extracting scientific terms from literature.
Automatic identification of meaningful topics (“emergent categories”) is mainly about identifying phrases that are both representative of a specific corpus and convey knowledge to chemists. By modelling the distribution of words based on their location, we are able to build up a vocabulary of emergent multi-word terms, while simultaneously using discovered patterns to identify those that are meaningful to chemists.

Machine Learning from Chemistry
Mapping spectra to molecules
We apply a variety of deep learning based techniques to gain insights based on our repositories of mass spectroscopy and NMR data from ChemSpider, to assign the biological relevance of molecular formulae. The purpose of this work was to identify for a particular mass range which molecular formulae were the most likely to have been found in a biological sample.
We have also applied deep learning to the problem of reliably assigning peaks in both 13C and proton NMR spectra from NMRShiftdb and Marinlit. We found that different topologies allow us to build models that were suitable for reliable regression analysis, with groups that have complex patterns (e.g. generic methyl groups) requiring different training to more specific functional groups (e.g. methoxy groups).
We have found, through our chemical data machine learning work, that superior results are often found by adopting an ensemble approach to neural nets which allows for flexible levels of feature engineering. Instead of over-encoding the data, we generally adopt different designs that allow the algorithms to learn the nuances of chemistry directly from the data.
For more information see the poster presented at GCC 2017 about this project.
Molecule Recommendation
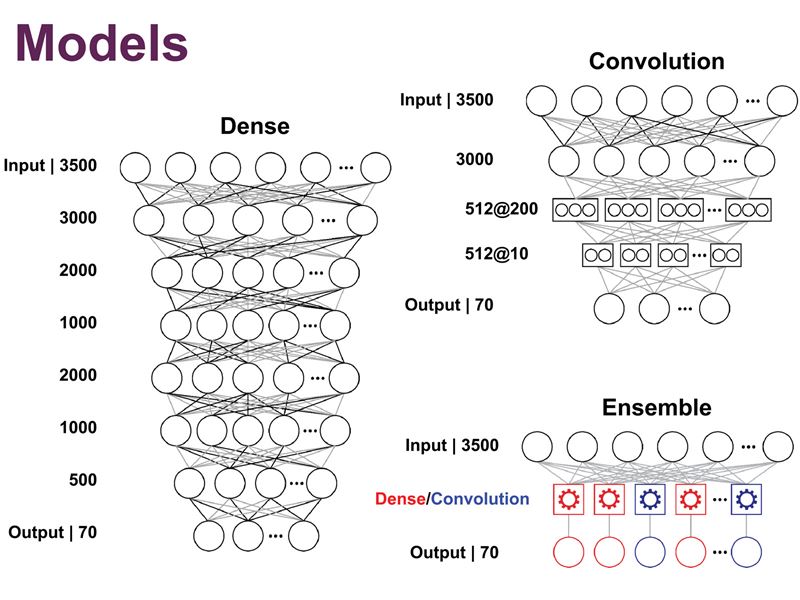
In order to make it easier for users to find molecules relevant to their needs, we have been exploring techniques that draw upon heterogeneous data sources.
We have looked at what we can use as proxies for, or models of, user behaviour. This enables us to recommend molecules on the basis of the contexts in which the molecules are synthesised and applied, as well as their structural similarities.
We use this information to help integrate molecule information with other relevant data sources, so that it is possible to find associations between molecules and authors, scientific papers, reactions, categories and even countries.
Behavioural Mining
Log file parsing
We have an active community who have millions of daily interactions with our web sites. To help improve these services we have to mine the data, and this requires the use of our well-established log parsing pipeline. This pipeline enables us to differentiate between robot traffic and human activity on our websites. This helps us to understand how robots and humans use our website and inform our website development programme.
This is built using Python and MongoDB. Using a data-lake architecture, our multistep pipeline trims down log files to select the actual data we require. This pipeline is run daily to process the millions of interactions with our websites. Our pipeline uses a range of data sources, heuristics and pattern matching algorithms.
Article recommendation
We have designed a range of article recommendation systems that help readers to find relevant articles based on:
- citations
- textual content
- user behaviour
- a combination of the above.
We have evaluated these methods with scientists and their feedback enables us to understand what type of system is most useful in a research context. For further information see a presentation of the results.
Trend analysis
In order to identify and understand emergent research trends in the chemical sciences, we have developed a tool for deriving associations between search terms and topics in the literature.
This tool uses entropy-based measures to evaluate associations between popular search terms. For example, using this tool, we can show the dramatic growth in solar cells as an application of perovskite-based materials.

Business Analytics
The majority of our work is in business analytics. We have contribute to a number of RSC based reports (e.g. analyses of HESA and UCAS data and investigation of Gender biases in our products and workflows). We also undertake analytics for forecasting, sales predications and development of KPIs.
Further Information
There is more information about our projects in our publications webpage and Data Science blog.
Contact Data Science
- Email:
- Send us an email